 AI时代下的GPU生存工具包:每个开发人员必须了解的最基本知识
AI时代下的GPU生存工具包:每个开发人员必须了解的最基本知识
# 1 CPU知识为何不再足够
在当今的人工智能时代,大多数开发者都是按照CPU的方式进行训练。这种认知也已经成为我们学术中的一部分,因此很自然地会以CPU为导向来思考和解决问题。
然而,CPU 的问题在于它们依赖于串行架构。在当今世界中,我们依赖大量并行任务的情况下,CPU 无法很好地处理这些场景。
因此,开发者面临着如下问题。
执行并行任务
CPU 传统上是线性运行的,一次执行一条指令。这种限制源于这样一个事实:CPU 通常具有一些针对单线程性能进行优化的强大内核。当面临多个任务时,CPU会分配其资源来逐个处理每个任务,从而导致指令的顺序执行。在需要同时关注众多任务的情况下,这种方法变得低效。
尽管我们通过诸如多线程等技术来提高CPU性能,但CPU的基本设计理念是优先考虑顺序执行。
高效运行AI模型
AI 模型采用 Transformer 等先进架构,利用并行处理来增强性能。与顺序运行的旧递归神经网络 (RNN) 不同,GPT 等现代 Transformer 可以同时处理多个单词,从而提高训练效率和能力。因为当我们并行训练时,会产生更大的模型,而更大的模型会产生更好的输出。
并行的概念已从自然语言处理扩展到图像识别等其他领域。例如,图像识别架构 AlexNet 通过同时处理图像的不同部分,展示了并行处理的威力,从而实现准确的模式识别。
然而,CPU 的设计侧重于单线程性能,很难充分挖掘并行处理的潜力。它们难以有效分配和执行复杂AI模型所需的大量并行计算。
# 2 GPU驱动开发如何解决这些问题
GPU 核心的大规模并行性
与 CPU 中更大、更强大的内核相比,工程师设计的 GPU 具有更小、高度专业化的内核。该架构允许 GPU 同时执行多个并行任务。
GPU 中的大量核心非常适合依赖于并行性的工作负载,例如图形渲染和复杂的数学计算。
如下图所示,5.3.2使用 GPU 并行性来减少复杂任务所需的时间。
AI 模型中使用的并行性
人工智能模型,特别是基于 TensorFlow (opens new window) 等深度学习框架构建的模型,表现出高度的并行性。神经网络训练涉及大量矩阵运算,而 GPU 凭借其庞大的核心数量,擅长并行化这些运算。 TensorFlow 与其他流行的深度学习框架一起进行优化,以利用 GPU 的能力来加速模型训练和推理。
如下图所示,5.3.3使用 GPU 的强大功能来训练神经网络。
# 3 GPU和CPU有什么区别
CPU
串行架构
中央处理单元 (CPU) 的设计重点是顺序处理。它们擅长线性执行一组指令。CPU 针对需要高单线程性能的任务进行了优化,例如:
- 通用计算
- 系统操作
- 处理涉及条件分支的复杂算法
并行任务的核心数量有限
CPU 的核心数量较少,在消费级处理器中通常为 2-16 个核心。每个内核都能够独立处理自己的指令集。
GPU
并行架构
图形处理单元(GPU)采用并行架构设计,使其能够高效地执行并行处理任务。这有利于:
- 渲染图形
- 执行复杂的数学计算
- 运行可并行算法
GPU 通过将多个任务分解为更小的并行子任务来同时处理多个任务。
数千个内核用于并行任务
与 CPU 不同,GPU 拥有更多的核心,通常有数千个。这些内核被组织成流式多处理器 (SM) 或类似的结构。丰富的内核使 GPU 能够同时处理大量数据,非常适合并行任务,例如图像和视频处理、深度学习和科学模拟。
# 4 GPU类型
通用 Gpu
通用 GPU 实例(P3 和 P4 实例)适用于广泛的工作负载,包括机器学习训练和推理、图像处理和视频编码。它们的平衡性能使它们成为各种计算任务的理想选择。
推理优化的 GPU
推理是运行已经训练好的 AI 模型并对实时数据进行预测或任务求解的过程。推理优化的 GPU 实例(P5 和 Inf1 实例)在低延迟和成本效率至关重要的情况下表现出色,特别适用于机器学习推理任务。
图形优化的 GPU
图形优化的 GPU 实例(G4 实例)专门设计用于处理图形密集型任务,如视频游戏开发中的 3D 图形渲染。这些实例非常适合需要处理大量图形数据的应用程序。
托管 GPU
Amazon SageMaker 是一种托管服务,为机器学习提供了易于使用的 GPU 实例。它提供对多种 GPU 实例(包括 P3、P4 和 P5 实例)的访问,适用于想要轻松开始机器学习而无需管理底层基础设施的组织。
# 5 使用 Nvidia 的 CUDA 进行 GPU 驱动开发
CUDA 是 NVIDIA 开发的并行计算平台和编程模型,使开发人员能够利用 GPU 加速器的强大功能来加速其应用程序。
# 5.1 Linux安装CUDA
从上面的链接下载基本安装程序以及驱动程序安装程序
转到主文件夹中的
.bashrc(如果使用其他shell则使用对应的配置文件)在配置文件中添加以下行:
export PATH="/usr/local/cuda-12.3/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/cuda-12.3/lib64:$LD_LIBRARY_PATH"1
21
2然后执行以下命令:
sudo apt-get install cuda-toolkit sudo apt-get install nvidia-gds1
21
2
# 5.2 基本命令
lspci | grep VGA识别并列出系统中的 GPU。

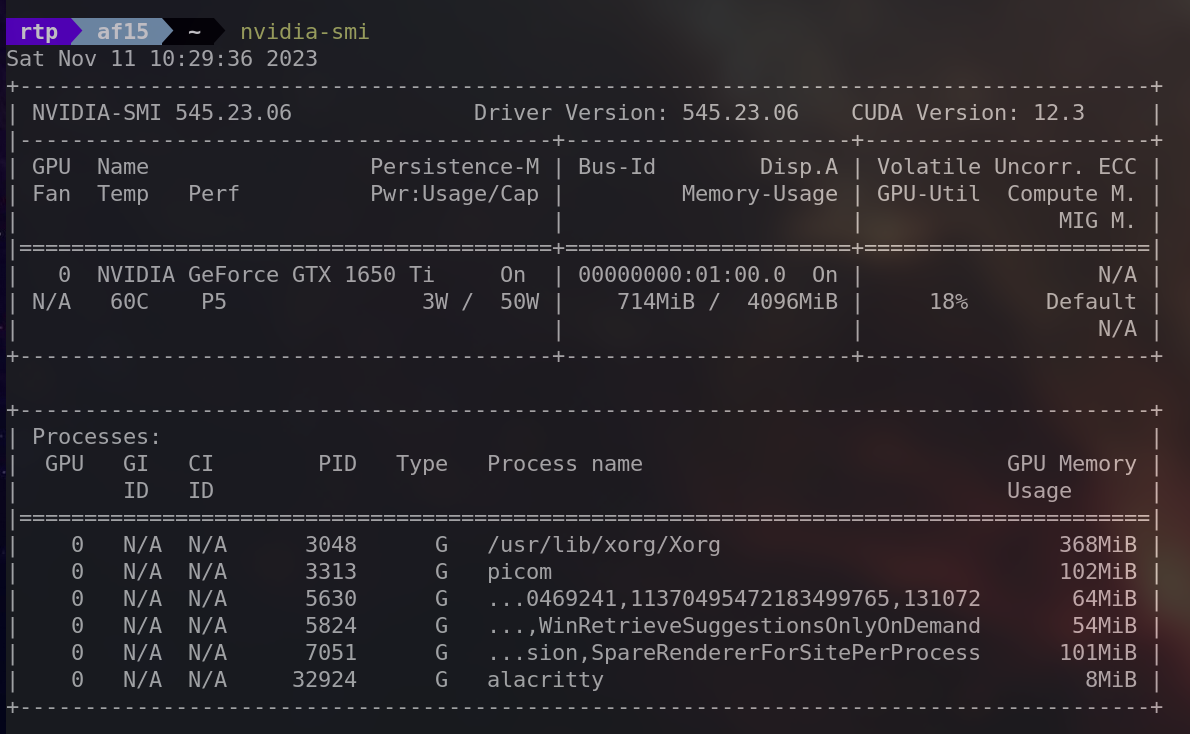
nvidia-smi“NVIDIA 系统管理界面”,它提供有关系统中 NVIDIA GPU 的详细信息,包括利用率、温度、内存使用情况等。
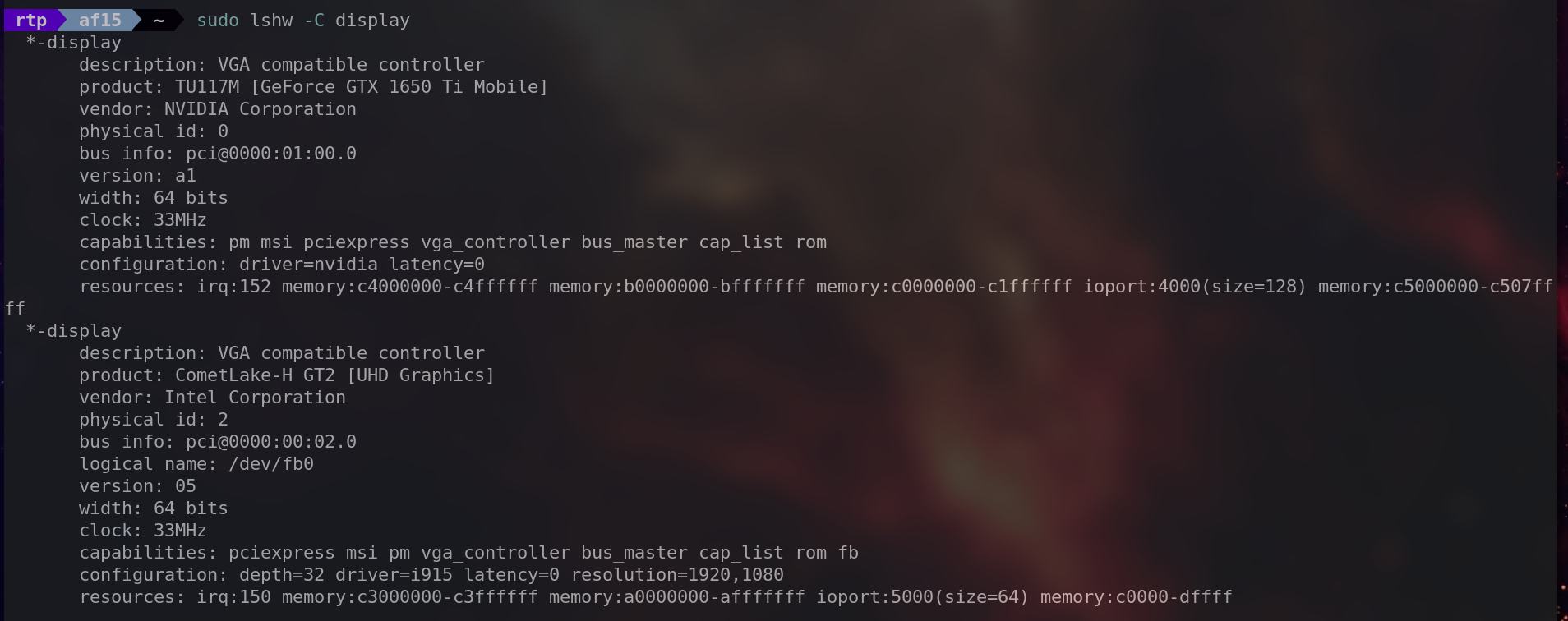
sudo lshw -C display提供有关系统中显示控制器(包括显卡)的详细信息。
inxi -G提供有关图形子系统的信息,包括有关 GPU 和显示器的详细信息。
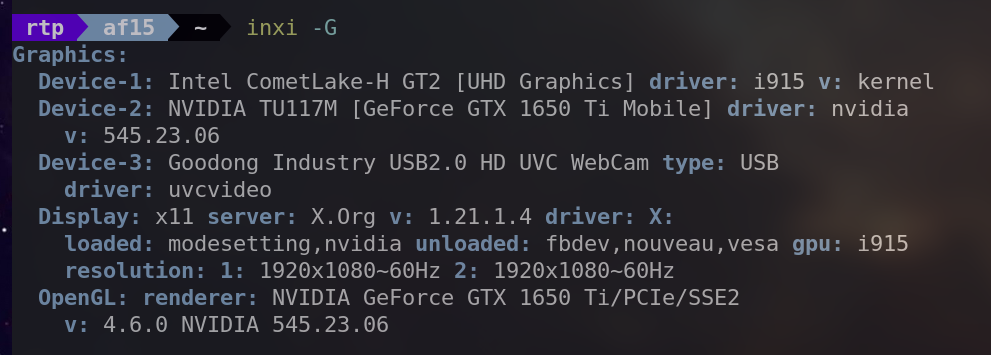
sudo hwinfo --gfxcard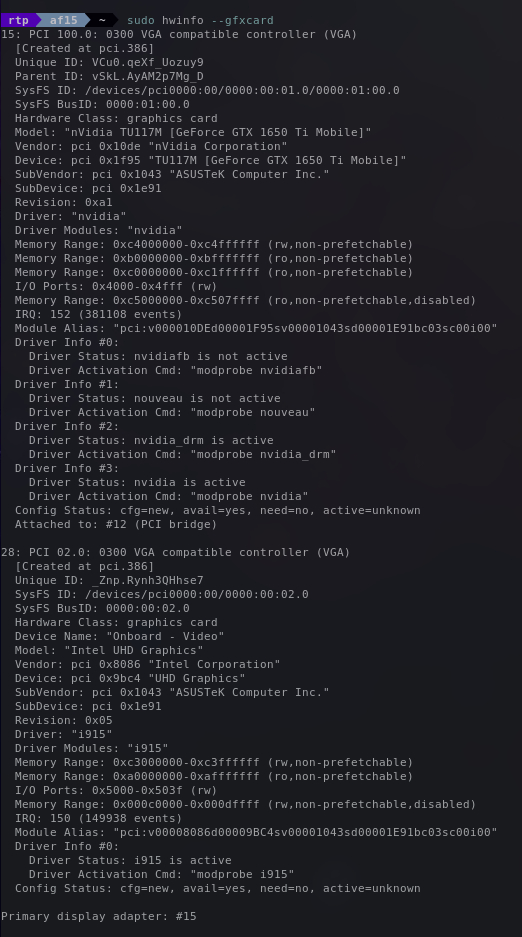
# 5.3 开始使用CUDA框架
当我们安装了 CUDA 框架后,让我们开始执行展示其功能的操作。
# 5.3.1 数组加法问题
数组加法问题是演示 GPU 并行化的一个合适问题。考虑以下数组:
数组
数组
我们需要存储每个元素的和并将其存储在数组中。我们需要存储每个元素的和并将其存储在数组中。
就像
如果CPU要执行这样的操作,它将执行如下代码所示的操作。
#include <stdio.h> int a[] = {1,2,3,4,5,6}; int b[] = {7,8,9,10,11,12}; int c[6]; int main() { int N = 6; // Number of elements for (int i = 0; i < N; i++) { c[i] = a[i] + b[i]; } for (int i = 0; i < N; i++) { printf("c[%d] = %d", i, c[i]); } return 0; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
181
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这种方法是逐个遍历数组元素并依次执行加法。然而,当处理大量数字时,这种方法由于其顺序性质而变得缓慢。
为了解决这个限制,GPU 通过并行化加法过程提供了一种解决方案。与依次执行运算的 CPU 不同,GPU 可以同时执行多项加法。例如,运算和可以借助GPU并行化同时执行。
利用CUDA,我们将使用内核文件 (.cu) 进行展示。实现并行加法的代码如下:
__global__ void vectorAdd(int* a, int* b, int* c) {
int i = threadIdx.x;
c[i] = a[i] + b[i];
return;
}
2
3
4
5
2
3
4
5
__global__说明符表明该函数是一个内核函数,将在 GPU 上调用。vectorAdd采用三个整数指针(、 和 )作为参数,表示要相加的向量。threadIdx.x检索当前线程的索引(在一维网格中)。- 向量 和 的相应元素之和存储在向量 中。
现在我们来看看主要功能。创建指针 cudaA 、 cudaB 和 cudaC 来指向 GPU 上的内存。
// 利用 CUDA 使用并行计算加法的函数
int main() {
int a[] = {1,2,3};
int b[] = {4,5,6};
int c[sizeof(a) / sizeof(int)] = {0};
// 创建指向 GPU 的指针
int* cudaA = 0;
int* cudaB = 0;
int* cudaC = 0;
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
使用 cudaMalloc ,在 GPU 上为向量 cudaA、cudaB 和 cudaC 分配内存。
// 在GPU中分配内存
cudaMalloc(&cudaA,sizeof(a));
cudaMalloc(&cudaB,sizeof(b));
cudaMalloc(&cudaC,sizeof(c));
2
3
4
2
3
4
内核函数 vectorAdd 使用一个块和等于向量大小的多个线程启动。
// 用一个程序块和与向量大小相等的线程数启动内核
vectorAdd <<<1, sizeof(a) / sizeof(a[0])>>> (cudaA, cudaB, cudaC);
2
2
结果向量 cudaC 从GPU复制回主机。
// 将结果向量复制回主机
cudaMemcpy(c, cudaC, sizeof(c), cudaMemcpyDeviceToHost);
2
2
然后我们可以照常打印结果
// 打印结果
for (int i = 0; i < sizeof(c) / sizeof(int); i++) {
printf("c[%d] = %d", i, c[i]);
}
return 0;
}
2
3
4
5
6
7
2
3
4
5
6
7
为了执行此代码,我们将使用 nvcc 命令。我们将得到输出为:
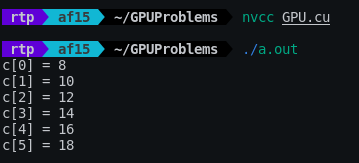
这是完整的代码 (opens new window)供读者参考。
# 5.3.2 使用 GPU 在 Python 中优化图像生成
本节探讨使用 GPU 处理来优化性能密集型任务,例如图像生成。
Mandelbrot 集是一种数学构造,它根据规定方程中特定数字的行为形成复杂的视觉模式。生成一个这样的图案需要耗费大量资源。在下面的代码片段中,您可以观察到使用 CPU 处理生成 Mandelbrot 集的传统方法,该方法速度很慢。
# 导入必要的库
from matplotlib import pyplot as plt
import numpy as np
from pylab import imshow, show
from timeit import default_timer as timer
# 计算给定点 (x, y) 的 Mandelbrot 集的函数
def mandel(x, y, max_iters):
c = complex(x, y)
z = 0.0j
# 迭代检查该点是否在 Mandelbrot 集中
for i in range(max_iters):
z = z*z + c
if (z.real*z.real + z.imag*z.imag) >= 4:
return i
# 如果在最大迭代次数内,则将其视为集合的一部分
return max_iters
# 在指定区域内创建 Mandelbrot 分形的函数
def create_fractal(min_x, max_x, min_y, max_y, image, iters):
height = image.shape[0]
width = image.shape[1]
# 根据指定区域计算像素大小
pixel_size_x = (max_x - min_x) / width
pixel_size_y = (max_y - min_y) / height
# 在图像中迭代每个像素并计算Mandelbrot值
for x in range(width):
real = min_x + x * pixel_size_x
for y in range(height):
imag = min_y + y * pixel_size_y
color = mandel(real, imag, iters)
image[y, x] = color
# 为 Mandelbrot 集创建一个空白图像数组
image = np.zeros((1024, 1536), dtype=np.uint8)
# 记录性能测量的开始时间
start = timer()
# 在指定的区域和迭代次数内生成Mandelbrot集合
create_fractal(-2.0, 1.0, -1.0, 1.0, image, 20)
# 计算创建 Mandelbrot 集所需的时间
dt = timer() - start
# 打印生成 Mandelbrot 集所需的时间
print("Mandelbrot created in %f s" % dt)
# 使用 matplotlib 显示 Mandelbrot 集
imshow(image)
show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
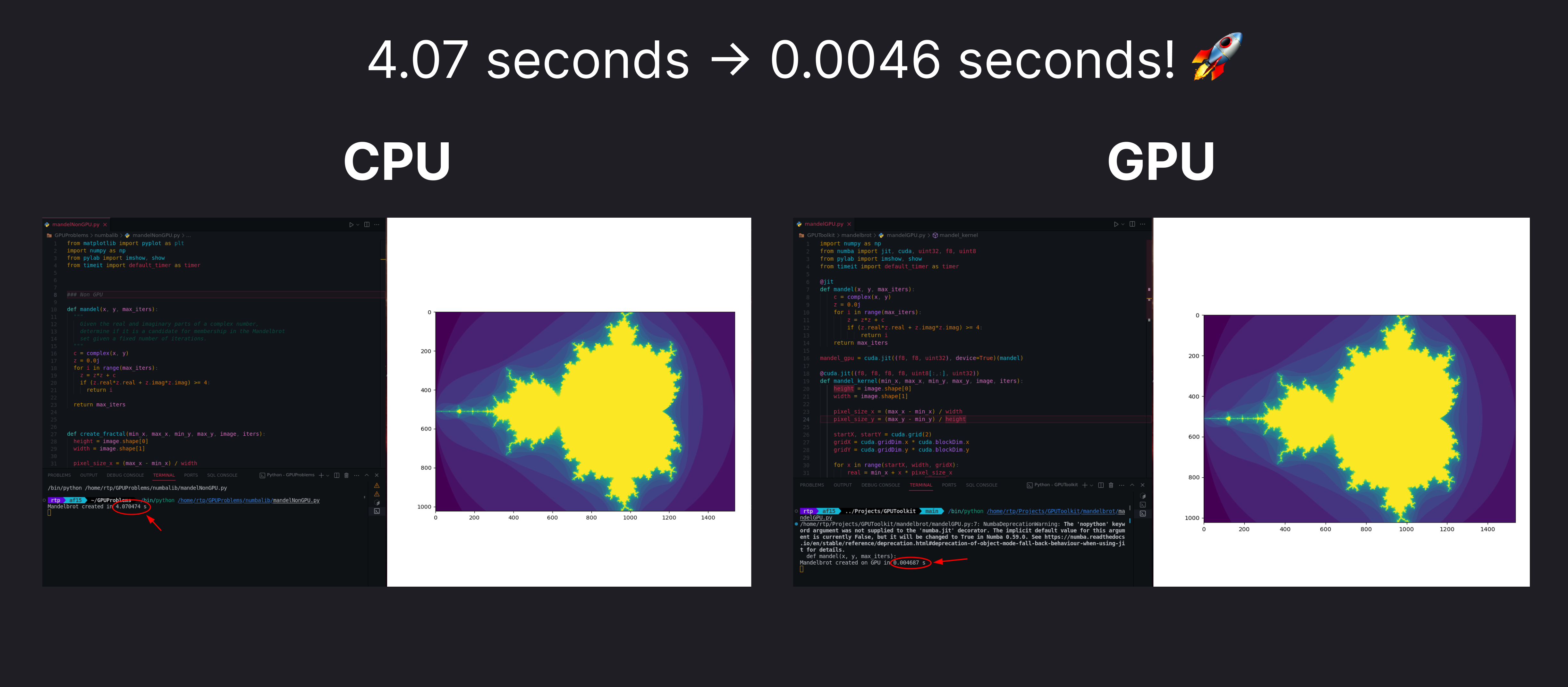
上面的代码在 4.07 秒内生成输出。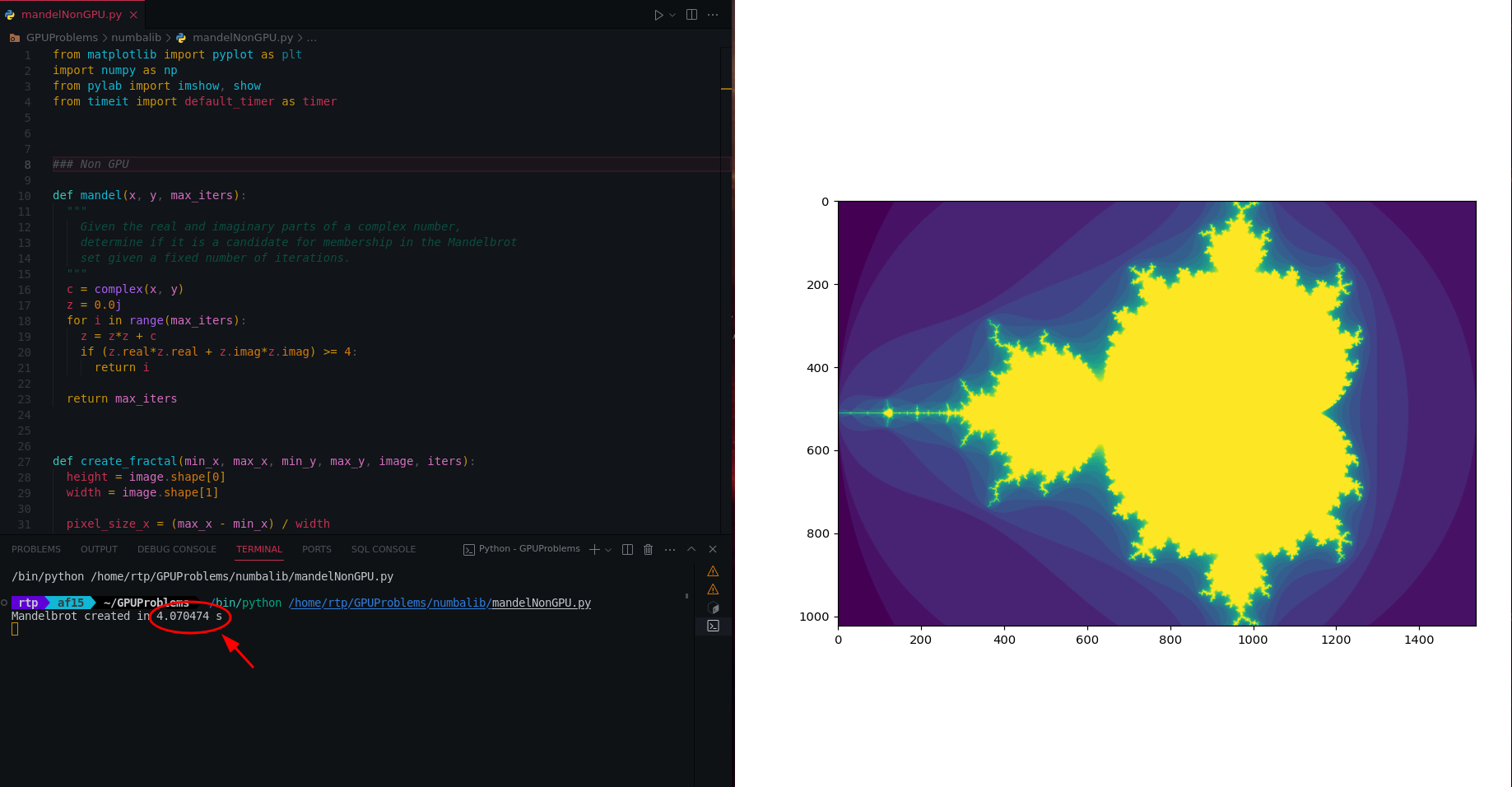
为了加快速度,我们可以使用 Numba (opens new window) 库将代码与 GPU 并行化,具体操作如下:
我们将从 numba 导入即时编译、用于 GPU 加速的 CUDA 以及其他工具库
import numpy as np from numba import jit, cuda, uint32, f8, uint8 from pylab import imshow, show from timeit import default_timer as timer1
2
3
41
2
3
4@jit装饰器指示 Numba 执行即时编译,将 Python 代码转换为机器代码以提高执行速度。@jit def mandel(x, y, max_iters): c = complex(x, y) z = 0.0j for i in range(max_iters): z = z*z + c if (z.real*z.real + z.imag*z.imag) >= 4: return i return max_iters1
2
3
4
5
6
7
8
9
101
2
3
4
5
6
7
8
9
10mandel_gpu是使用cuda.jit创建的 mandel 函数的 GPU 兼容版本。这允许将 mandel 逻辑卸载到 GPU。这是通过使用@cuda.jit装饰器并指定函数参数的数据类型(f8表示浮点数,``uint32表示无符号32位整数)来完成的。device=True` 参数指示该函数将在 GPU 上运行。mandel_gpu = cuda.jit((f8, f8, uint32), device=True)(mandel)11mandel_kernel函数被定义为在 CUDA GPU 上执行。它负责跨 GPU 线程并行生成 Mandelbrot 集。@cuda.jit((f8, f8, f8, f8, uint8[:,:], uint32)) def mandel_kernel(min_x, max_x, min_y, max_y, image, iters): height = image.shape[0] width = image.shape[1] pixel_size_x = (max_x - min_x) / width pixel_size_y = (max_y - min_y) / height startX, startY = cuda.grid(2) gridX = cuda.gridDim.x * cuda.blockDim.x gridY = cuda.gridDim.y * cuda.blockDim.y for x in range(startX, width, gridX): real = min_x + x * pixel_size_x for y in range(startY, height, gridY): imag = min_y + y * pixel_size_y image[y, x] = mandel_gpu(real, imag, iters)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
171
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17现在,我们可以在
create_fractal_gpu函数中使用 GPU 加速的 Mandelbrot 集生成。该函数分配 GPU 内存,启动 GPU 内核 (mandel_kernel),并将结果复制回 CPU。def create_fractal_gpu(min_x, max_x, min_y, max_y, image, iters): # Step 1: 为图像分配GPU内存 d_image = cuda.to_device(image) # Step 2: 定义GPU并行化的线程和块数 threadsperblock = (16, 16) blockspergrid_x = int(np.ceil(image.shape[1] / threadsperblock[0])) blockspergrid_y = int(np.ceil(image.shape[0] / threadsperblock[1])) blockspergrid = (blockspergrid_x, blockspergrid_y) # Step 3: 测量开始时间 start = timer() # Step 4: 启动 GPU 内核(mandel_kernel)在 GPU 上计算 Mandelbrot 集。 mandel_kernel[blockspergrid, threadsperblock](min_x, max_x, min_y, max_y, d_image, iters) # Step 5: 等待 GPU 完成其工作(同步) cuda.synchronize() # Step 6: 测量GPU处理所需的时间 dt = timer() - start # Step 7: 将结果从 GPU 内存复制回 CPU d_image.copy_to_host(image) # Step 8: 显示 Mandelbrot 集图像 print("Mandelbrot created on GPU in %f s" % dt) imshow(image) show()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
291
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
上面的代码在 0.0046 seconds 中执行。这比我们之前的基于 CPU 的代码要快得多。
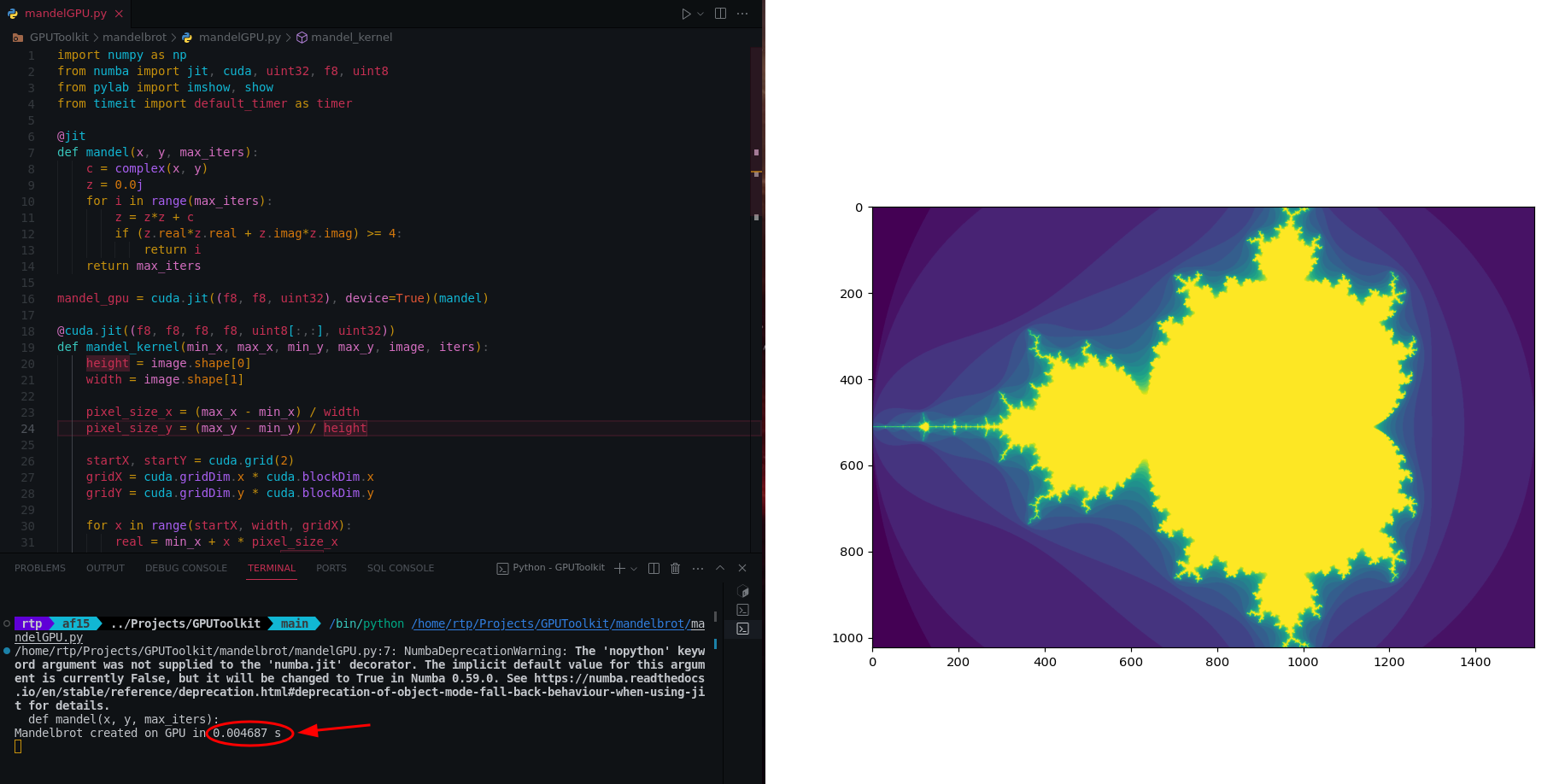
这是完整的代码 (opens new window)供读者参考。
# 5.3.3 使用 GPU 训练猫狗神经网络
我们现在看到的热门话题之一是 GPU 如何在人工智能中使用,因此为了证明我们将创建一个神经网络来区分猫和狗。我们将使用以下代码训练和使用猫与狗模型,其中使用了卷积神经网络(CNN),您可以阅读有关它的更多详细信息 (opens new window)。
先决条件
CUDA
Tensorflow -> 可以通过
pip install tensorflow[and-cuda]安装我们将使用来自kaggle (opens new window)的猫和狗的数据集
下载完成后,解压,将训练文件夹中的猫和狗的图片整理到不同的子文件夹中,如下图所示。
导入库
pandas和numpy用于数据操作。Sequential用于在神经网络中创建线性层堆栈。Convolution2D、``MaxPooling2D、Dense和Flatten` 是用于构建卷积神经网络 (CNN) 的层。ImageDataGenerator用于在训练期间进行实时数据增强。
import pandas as pd import numpy as np from keras.models import Sequential from keras.layers import Convolution2D, MaxPooling2D, Dense, Flatten from keras.preprocessing.image import ImageDataGenerator1
2
3
4
51
2
3
4
5初始化卷积神经网络
classifier = Sequential()11加载训练数据
train_datagen = ImageDataGenerator( rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True ) test_datagen = ImageDataGenerator(rescale=1./255) training_set = train_datagen.flow_from_directory( './training_set', target_size=(64, 64), batch_size=32, class_mode='binary' ) test_set = test_datagen.flow_from_directory( './test_set', target_size=(64, 64), batch_size=32, class_mode='binary'1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
201
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20构建 CNN 架构
classifier.add(Convolution2D(32, 3, 3, input_shape=(64, 64, 3), activation='relu')) classifier.add(MaxPooling2D(pool_size=(2, 2))) classifier.add(Flatten()) classifier.add(Dense(units=128, activation='relu')) classifier.add(Dense(units=1, activation='sigmoid'))1
2
3
4
51
2
3
4
5编译模型
classifier.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])11训练模型
classifier.fit(training_set, epochs=25, validation_data=test_set, validation_steps=2000) classifier.save('trained_model.h5')1
21
2
一旦我们训练完模型,模型就会使用 classifier.save 存储在 .h5 文件中。在下面的代码中,我们将使用这个 trained_model.h5 文件来识别猫和狗。
import numpy as np
from keras.models import load_model
import keras.utils as image
def predict_image(imagepath, classifier):
predict = image.load_img(imagepath, target_size=(64, 64))
predict_modified = image.img_to_array(predict)
predict_modified = predict_modified / 255
predict_modified = np.expand_dims(predict_modified, axis=0)
result = classifier.predict(predict_modified)
if result[0][0] >= 0.5:
prediction = 'dog'
probability = result[0][0]
print("Probability = " + str(probability))
print("Prediction = " + prediction)
else:
prediction = 'cat'
probability = 1 - result[0][0]
print("Probability = " + str(probability))
print("Prediction = " + prediction)
# 加载训练好的模型
loaded_classifier = load_model('trained_model.h5')
# 示例用法
dog_image = "dog.jpg"
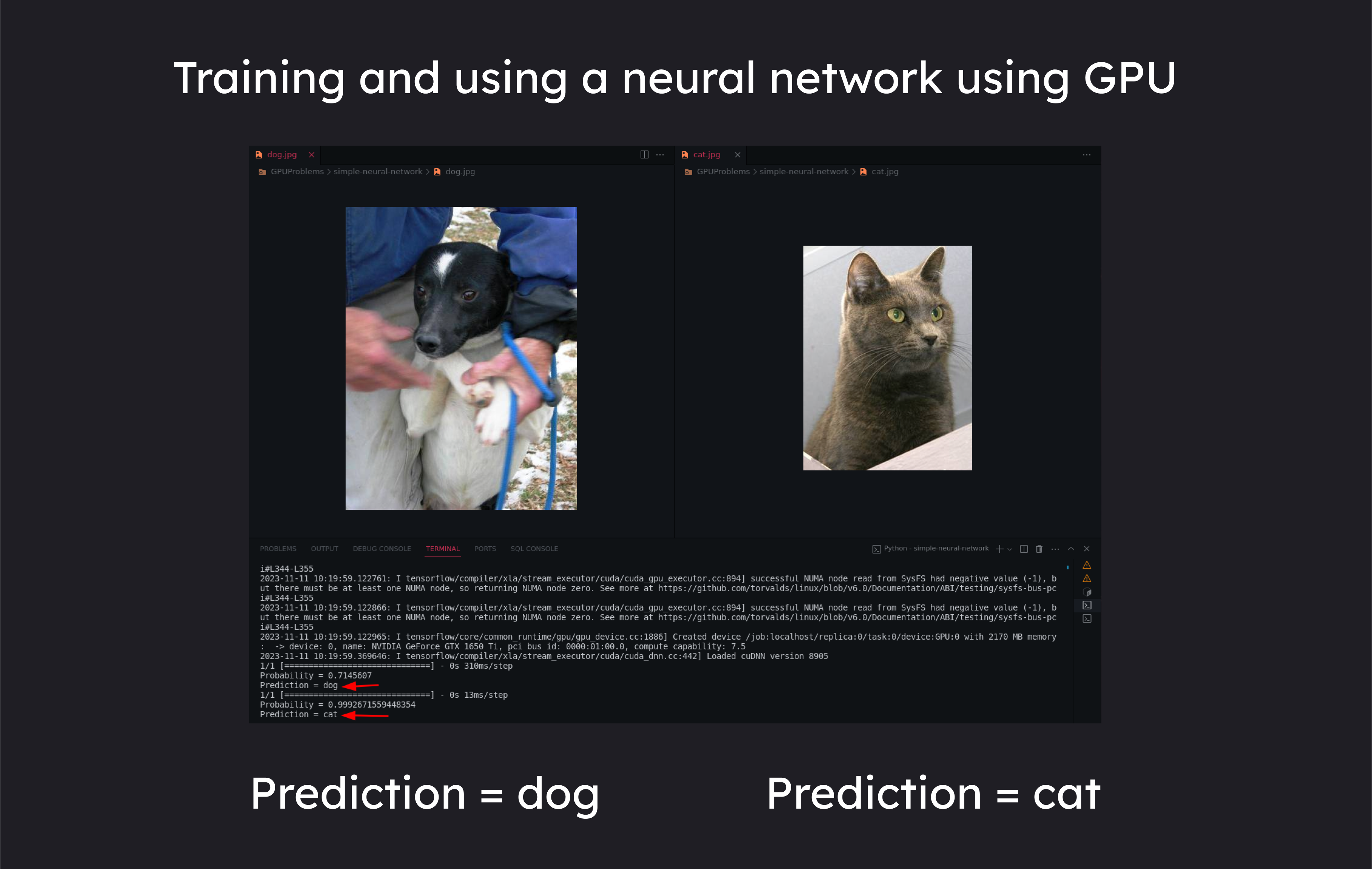
predict_image(dog_image, loaded_classifier)
cat_image = "cat.jpg"
predict_image(cat_image, loaded_classifier)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
输出结果如下:
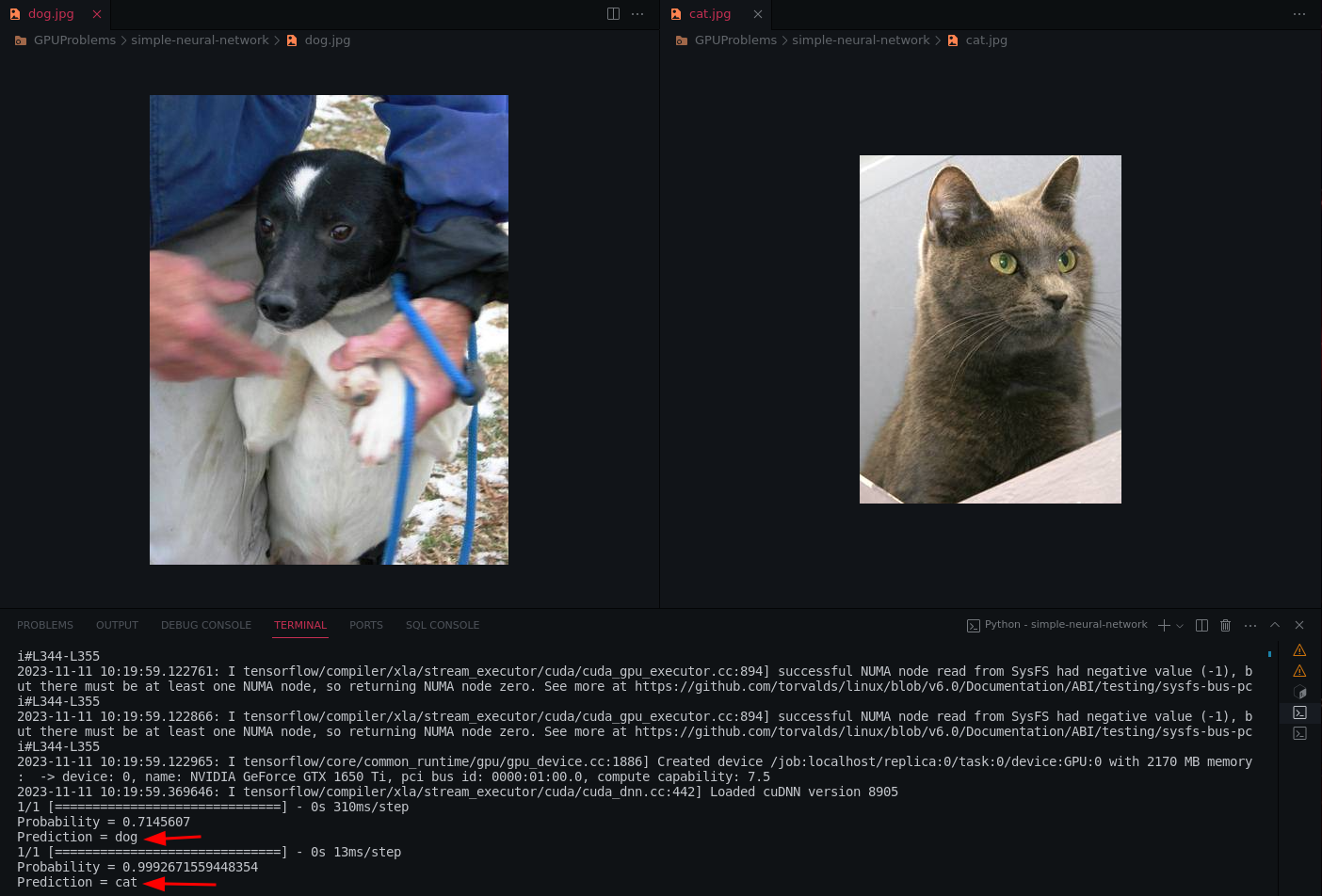
这是完整的代码 (opens new window)供读者学习参考。
# 6 结论
在即将到来的AI时代,GPU是一个不容忽视的东西,我们应该更加了解它的能力。随着我们从传统的串行算法过渡到日益流行的并行算法,GPU 成为加速复杂计算不可或缺的工具。 GPU 的并行处理能力在处理人工智能和机器学习任务固有的海量数据集和复杂的神经网络架构方面特别有优势。此外,GPU 的作用超出了传统的机器学习领域,在科学研究、模拟和数据密集型任务中找到了应用。事实证明,GPU 的并行处理能力有助于解决从药物发现、气候建模到金融模拟等各个领域的挑战。

